01
Industry Use Case
Bring governed digital labor intothe communications response workflow
Bring request routing, outage escalation, case progression, human takeover, and cross-team response into one communications operating chain.
Built for communications providers, network service teams, and high-volume service operations handling SLA risk and outage response.
Request routingOutage escalationSLA risk
Industry pressure
Communications teams are rarely missing ticket screens. They are blocked when conversations, cases, and escalation actions do not live on one execution chain.
From inbound contact and bot conversations to human takeover, outage escalation, case closure, and shift handoff, communications teams need one system that keeps queues, context, SLA, and accountability together.
02
Outages, escalations, and SLA-risk cases must reach the right owner quickly, but response stays unstable when queues, priorities, and states are inconsistent.
03
When handoffs cross shifts, bots transfer to humans, or complaints become complex, teams need promises, owners, and next steps written back into the core system instead of scattered through chat and verbal sync.
Core scenarios
Communications providers can start with these three service-response workflows
This page is not a full network operations suite. It is organized around the clearest response path: request routing, outage escalation, case progression, then cross-team response and handoff traceability.
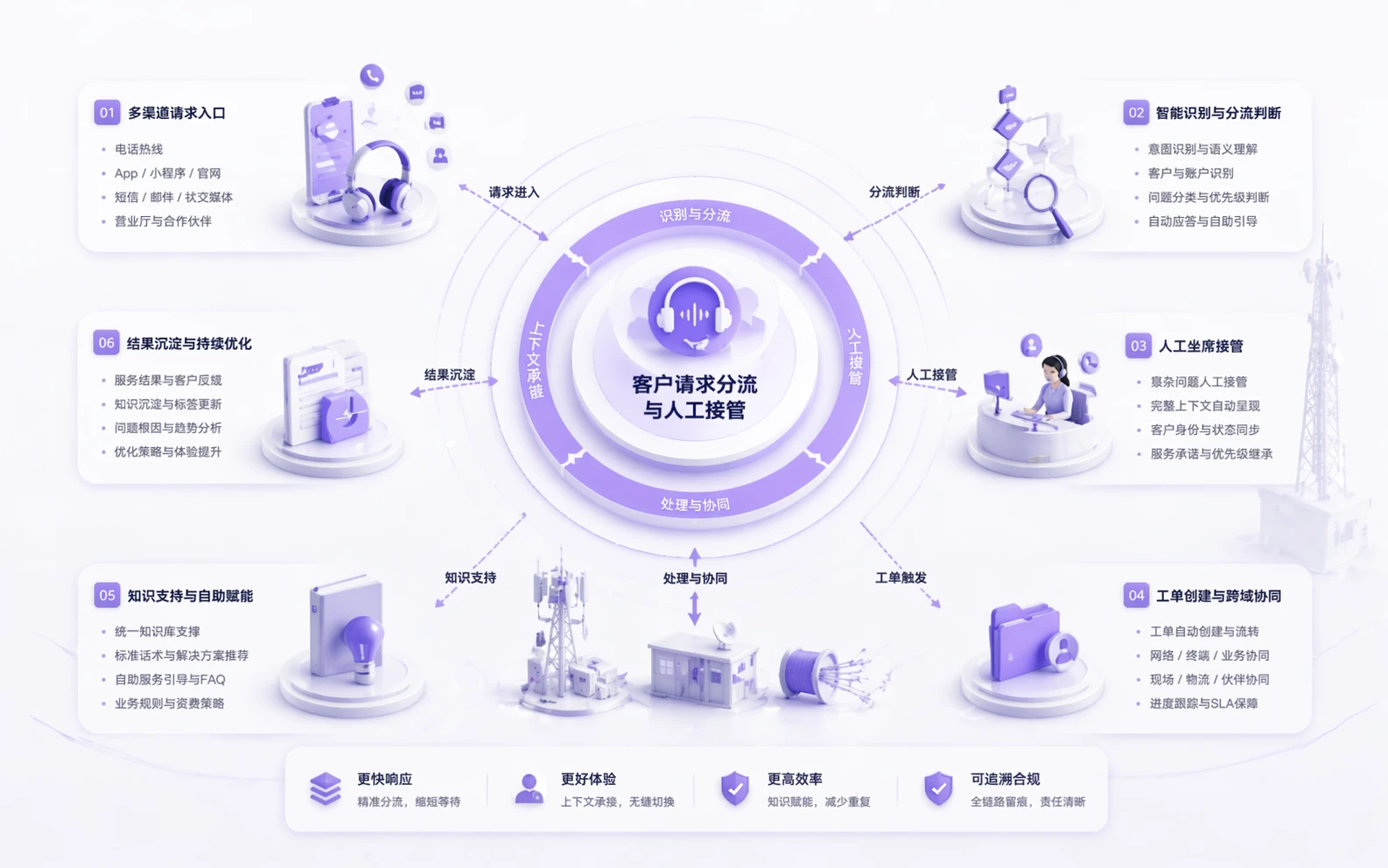
Request routing and human takeover
Route customer requests by type, priority, service policy, and bot-to-human conditions so the assignee receives queue context, customer state, and next-step guidance together.
More efficient triage
Less wait time
Better context at takeover
Outage escalation and case progression
Keep outage signals, SLA risk, priority changes, owner adjustments, and case progress inside one operating chain instead of stitching them across multiple lists and manual follow-up.
Less escalation delay
Faster recovery
More control over high-risk cases
Cross-team response and shift handoff
Align service, operations, technical, and shift teams around one workflow state while writing promises, handoff reasons, activity records, and knowledge feedback into the core system.
Less coordination friction
More transparent workflows
More stable ongoing service
Why NexusClaw
Communications teams need more than a bot that can reply. They need an execution system that can carry queues and escalation work.
What determines whether this works in production is whether customer context, case state, SLA risk, shift takeover, and knowledge feedback can live inside one governed system.
Start with the service desk, case, and takeover chain instead of a full OSS/BSS replacement
NexusClaw fits communications providers that need a governed path for request routing, human takeover, case handling, and escalation before anything heavier.
AI supports routing, summaries, prioritization, and next-step guidance without crossing handling boundaries
The system can classify cases, recommend knowledge, draft replies, surface SLA risk, and guide handoff, but it does not auto-close complex issues or bypass required human judgment.
Conversations, cases, shift handoff, and knowledge feedback stay on one record chain
Every bot transfer, owner change, escalation reason, activity trail, and outcome can write back into the core system so teams keep responding from the same facts.
See NexusClaw against a real communications response workflow
If you are evaluating how a communications provider can move request routing, outage escalation, case progression, and cross-team response into one governed chain, the most useful next step is a demo built around a real service workflow.